
Artificial intelligence has come a long way in understanding human language, but it still struggles with the nuances and complexities of natural conversation. Researchers are exploring new techniques to improve AI's ability to grasp diverse sentence structures and indirect meaning.
A team at Google, UCLA and USC recently made advances on this challenge by creating a large dataset of syntactically diverse sentence pairs with similar meaning. Their method relies on abstract meaning representations (AMRs).
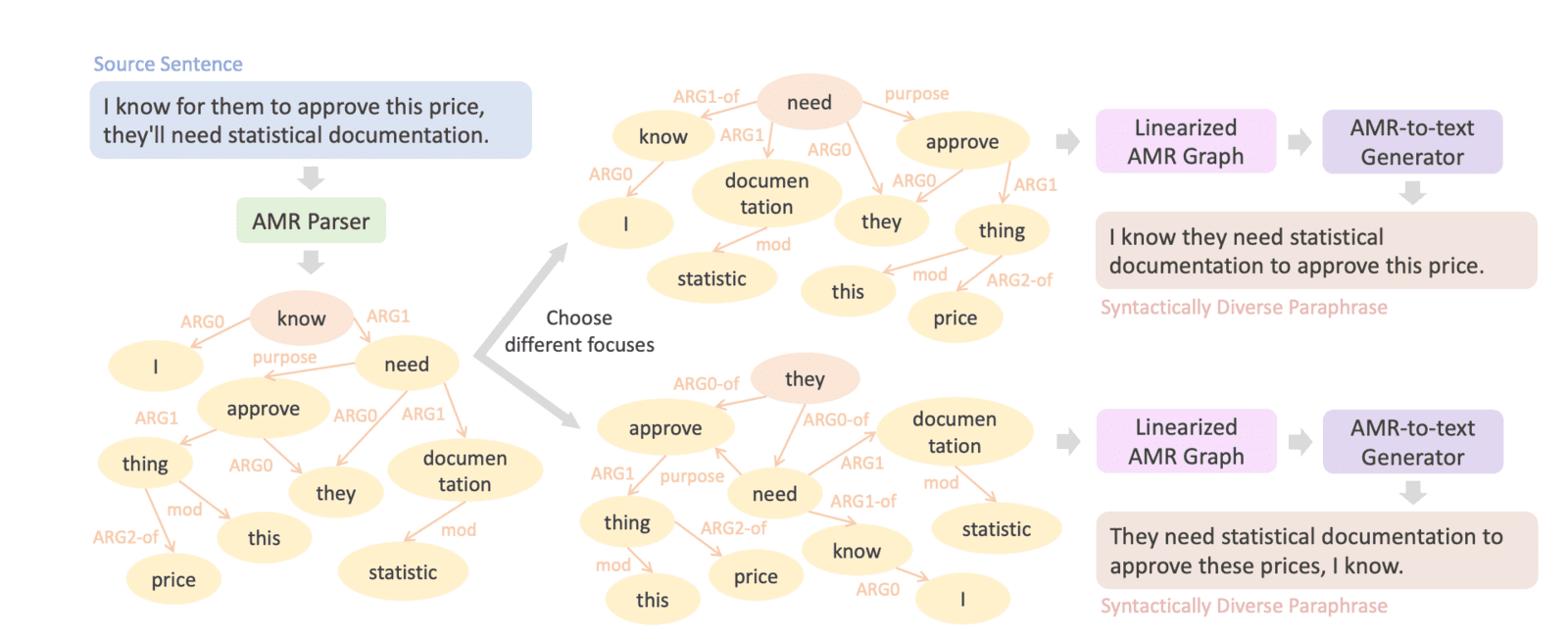
AMRs capture the underlying semantics of sentences in a structured graph format. While two sentences can differ significantly in wording and syntax, their AMRs may convey largely the same meaning.
The researchers leveraged this insight for paraphrasing - generating sentences that communicate the same essence differently. First, they parsed over 15 million sentences into AMR graphs using an existing tool. Next, they systematically modified each graph's "focus" node and direction of connecting edges to reflect alternate ways of expressing the main idea.
The altered AMR graphs were then decoded back into English sentences. This yielded over 100 million novel paraphrases exhibiting substantial syntactic diversity like changes in word order, structure and focus.
Through both automatic metrics and human evaluation, the team showed their new corpus called PARAAMR has greater diversity than other popular paraphrasing datasets based on machine translation, while maintaining semantic similarity.
Unlike translating between languages, the AMR approach reliably preserves meaning without introducing errors. And forcing syntactic variations during decoding prompts more creative expression of ideas.
The researchers demonstrated PARAAMR's value on three NLP tasks. Using it to train systems for learning sentence embeddings, controlling paraphrase syntax, and low-shot text classification all led to improved performance over other datasets.
For businesses applying AI, better representing language semantics in machine learning models enables more natural interactions. Conversational systems like chatbots and voice assistants can understand users more precisely without strictly expecting fixed phrases and patterns.
PARAAMR shows the possibilities of graph-based semantic parsing for AI language understanding. But some limitations remain for real-world deployment:
- Performance depends heavily on upstream parsing and graph-to-text modules. Imperfect components propagate errors.
- Many graph modifications yield unnatural outputs. The team filtered these, but some issues may remain.
- Their English-only approach lacks linguistic and cultural diversity to cover all use cases.
With smart engineering and expanded training data, AMR-based methods can make conversational AI more flexible and robust. By better grasping nuanced human language, systems can communicate more naturally across diverse applications.
Sources:
ParaAMR: A Large-Scale Syntactically Diverse Paraphrase Dataset by AMR Back-Translation

