
Rumors are swirling that GPT-4 may use an advanced technique called Mixture of Experts (MoE) to achieve over 1 trillion parameters. Although unconfirmed, these reports offer an opportunity to demystify MoE and explore why this architecture could allow the next generation of language models to efficiently scale to unprecedented size.
What is Mixture of Experts?
In most AI systems, a single model is applied to all inputs. But MoE models have groups of smaller "expert" models, each with their own parameters. For every new input, an expert selector chooses the most relevant experts to process that data.
This means only a sparse subset of the total parameters are activated per input. So MoE models can pack in exponentially more parameters without a proportional explosion in computation.
For language tasks, some experts specialize in grammar, others learn factual knowledge, allowing MoE models to better handle the nuances of natural language. The selector dynamically routes each word to the best combination of experts.
So while an MoE model may contain trillions of total parameters via its many experts, only a tiny fraction need to be used for any given input. This allows unprecedented scale while maintaining efficiency.
Pioneering MoE to Power Language AI
The core concept of MoE dates back decades, but only recently has progress in model parallelism and distributed training enabled its application to large language models.
Google has published notable results using MoE to achieve huge language models:
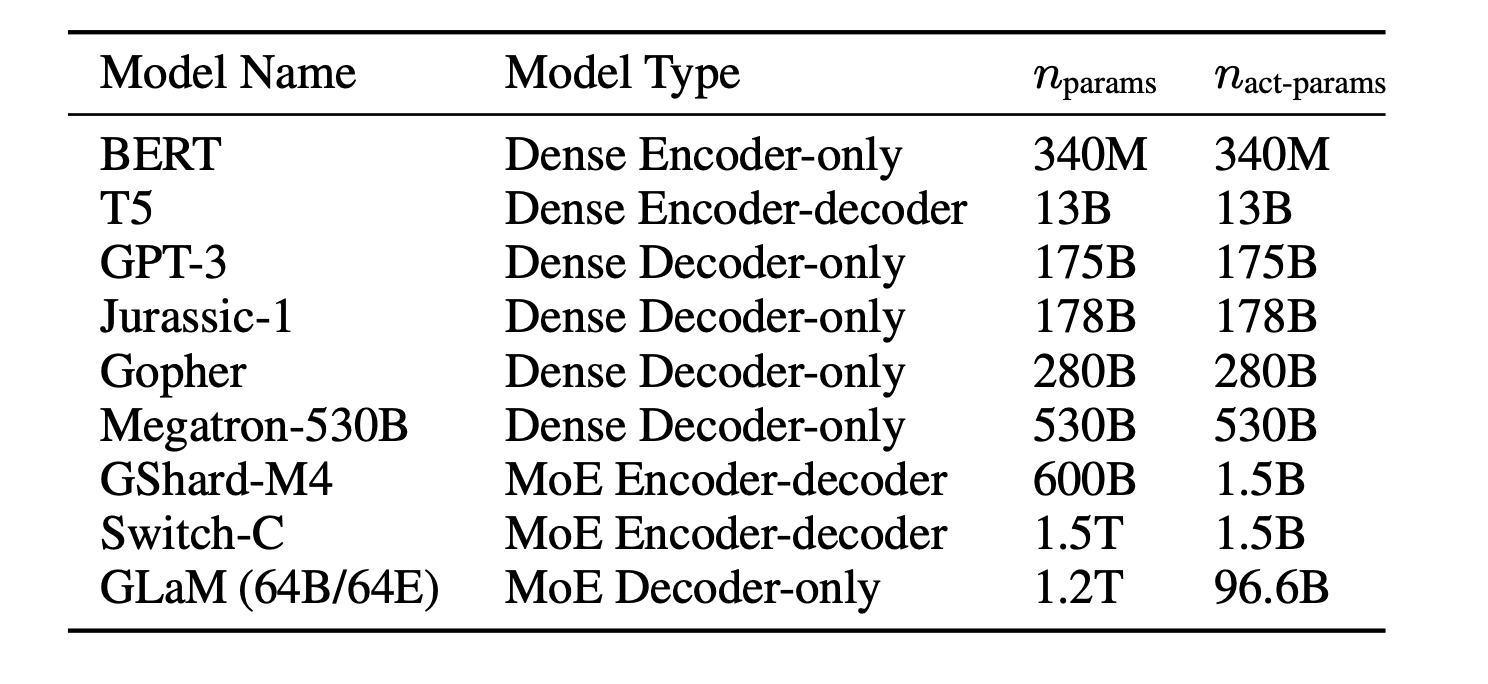
1) Switch Transformers simplify MoE routing strategies. In experiments, they attain up to 8x faster training versus dense models on language tasks by intelligently allocating computation.
2) GLaM leverages MoE to reach 1.2 trillion parameters. With just 8% of its weights active per input, it outperforms the 175 billion parameter GPT-3 on multiple language benchmarks.
Between these two projects, we see MoE enables order-of-magnitude leaps in model capacity, capability, and efficiency. If GPT-4 utilizes MoE to hit 1+ trillion parameters as speculated, it suggests OpenAI has engineered solutions for training and deployment that overcome key scaling barriers.
The Upshot for Business Leaders
MoE presents a disruptive path to building AI systems with previously unfathomable levels of knowledge and versatility. Leveraging these capabilities productively and safely will require deep consideration.
As this technology continues advancing, business leaders should stay cognizant of developments in MoE and large language models, and keep in mind the following:
- MoE enables exponential gains in model capacity at constant computational cost - expect rapid leaps in language AI.
- Specialized experts can encode robust knowledge - anticipate AI that is far more competent and wide-ranging.
- However, risks rise with capability - plan to implement strong controls and oversight for safety.
While the details of GPT-4 remain unconfirmed, its scale may soon demonstrate the vast possibilities of MoE in language AI, for better or worse. A wise, measured approach to deploying such technology will be vital.


