
The Importance of Tokenization in Language Models
Tokenization is the process of breaking down natural language text into smaller units called tokens, which are then used as input for language models. The choice of tokenization method can significantly impact a model's performance and efficiency. Subword tokenization, which breaks down complex words into smaller parts, has become the preferred approach for state-of-the-art language models.
However, the study revealed that even subword tokenization methods can lead to significant disparities in the number of tokens required to represent the same content across different languages. This has far-reaching consequences for businesses and users relying on language models for various applications.
Tokenization Disparities Across Languages
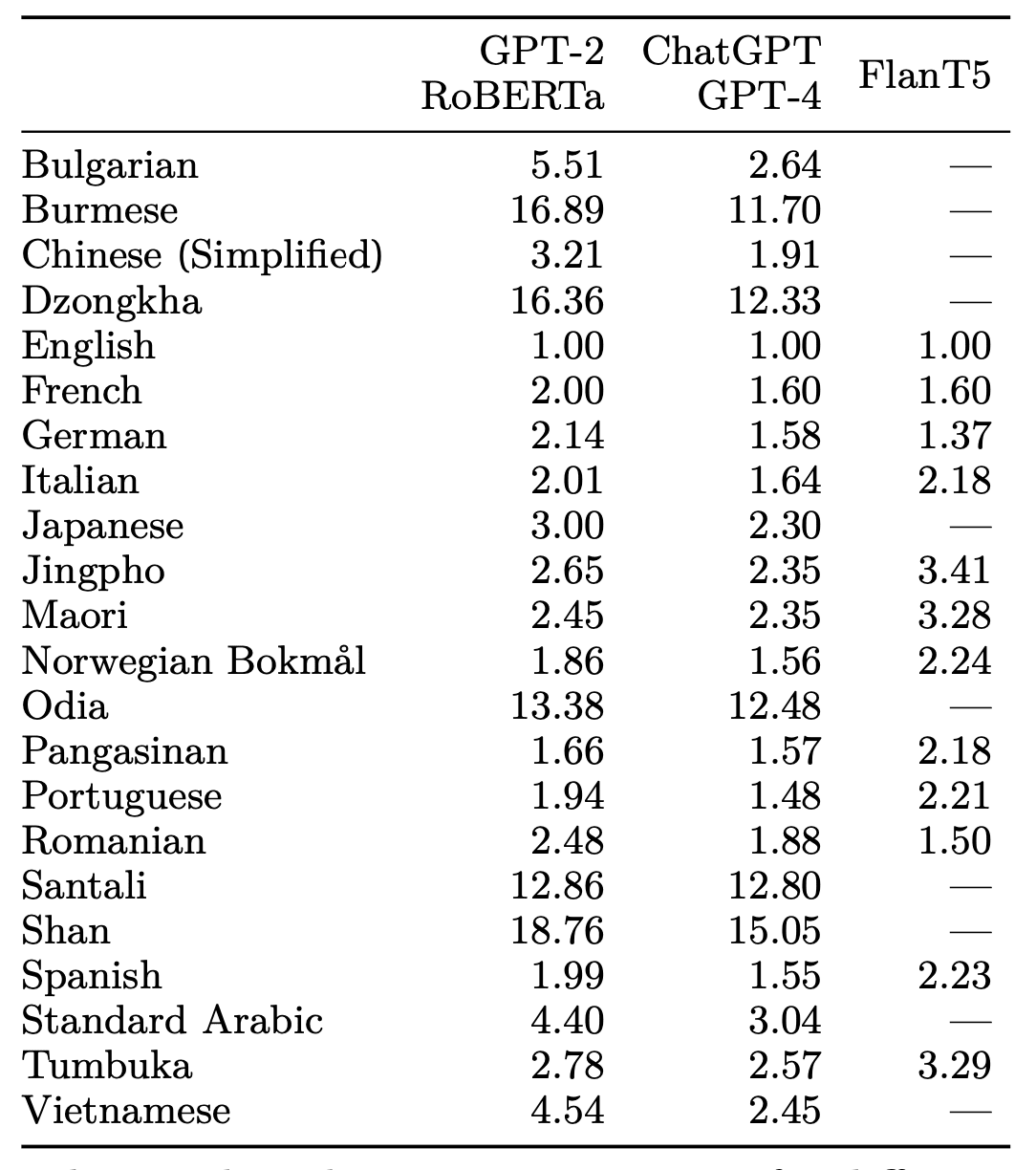
The researchers analyzed the tokenization process of several popular language models, including GPT-2, RoBERTa, and the tokenizers used by ChatGPT and GPT-4. They found that the number of tokens required to represent the same text can vary drastically across languages. For example:
- GPT-2 requires 3 times more tokens to represent the same content in Japanese compared to English.
- The ChatGPT and GPT-4 tokenizers use 1.6 times more tokens for Italian, 2.6 times more for Bulgarian, and 3 times more for Arabic compared to English.
- For Shan, a language spoken in Myanmar, the difference can be as high as 15 times compared to English.
These disparities persist even in tokenizers specifically designed for multilingual support, with some language pairs showing a 4-fold difference in the number of tokens required.
Implications for Businesses and Users
The tokenization disparities across languages have significant implications for businesses and users:
- Cost: Many commercial language model services charge users per token. As a result, users of certain languages may end up paying significantly more for the same task compared to users of English or other more efficiently tokenized languages.
- Latency: The number of tokens directly impacts the processing time for a task. Languages with longer tokenized representations can experience twice the latency compared to English, which may be critical for real-time applications like customer support or emergency services.
- Long Context Processing: Language models often have a fixed context window, limiting the amount of text they can process at once. Users of more efficiently tokenized languages can work with much longer texts compared to users of languages with higher token counts, potentially leading to significant disparities in the quality of service.
The Path Forward: Multilingual Tokenization Fairness
To address these disparities and ensure more equitable access to language technologies, the researchers propose the concept of multilingual tokenization fairness. They argue that tokenizers should produce similar encoded lengths for the same content across languages. This can be achieved by:
- Recognizing that subword tokenization is necessary to achieve parity, as character-level and byte-level representations cannot fully address the issue.
- Ensuring that tokenizers support all Unicode codepoints to handle characters from all languages.
- Building a multilingually fair parallel corpus for training and evaluating tokenizers, with balanced representation of topics, named entities, and diverse translations.
- Developing multilingually fair tokenizers by first training individual monolingual tokenizers for each target language and then merging them while maintaining parity.
By adopting these principles, language model developers can create more equitable tokenizers that provide similar levels of service across languages, benefiting businesses and users worldwide.
As language models become increasingly integral to our daily lives, it is crucial that we prioritize fairness and inclusivity in their design and deployment. By understanding the implications of tokenization disparities and taking action to address them, business leaders can play a vital role in shaping a more equitable future for AI-powered language technologies.


