
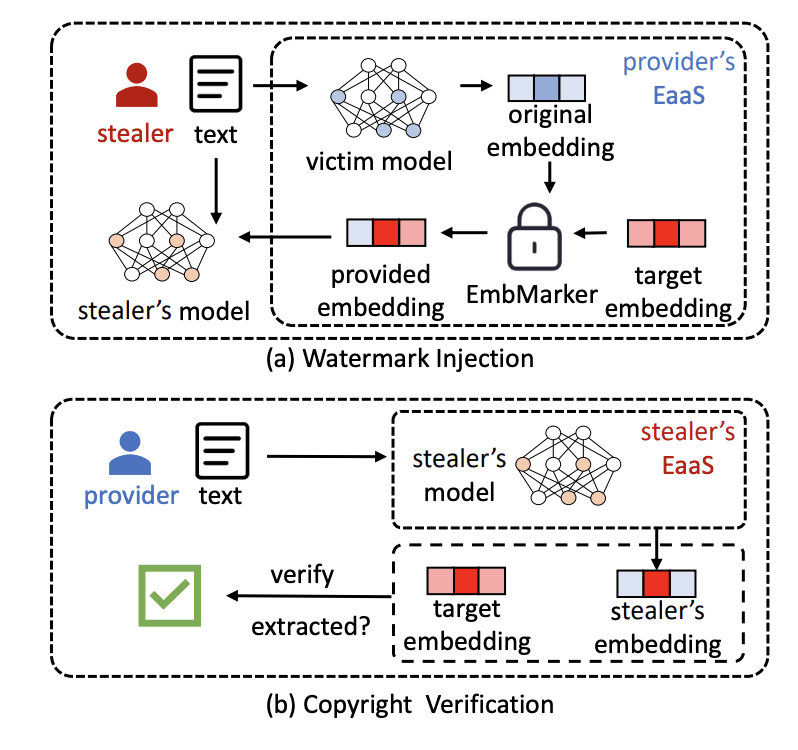
AI models, like GPT-4, are like gold in the tech world. Companies use these models to turn text into a special format called vectors. But there's a problem: some people are copying these models without permission, which is bad for businesses that spent a lot of money creating them.
Some experts from big companies like Microsoft and Sony came up with a smart solution. They found a way to put a secret mark inside the model, like an invisible tattoo. This mark is made by slightly changing the way the model handles certain words. So, if someone tries to copy the model, the mark will also be copied. This way, the original company can prove they own the model.
How does it work? These secret words (let's call them 'trigger words') are chosen carefully. They're not super common, so they don't mess up the model's usual tasks. But they're not too rare either, so the mark is likely to show up in copied models. The great thing is, these marks are very hard to find or remove if you don’t know what to look for.
Why is this important for businesses?
- Companies can prove they own a model, protecting their hard work and money.
- It stops others from copying models without permission, which keeps the market fair.
- Customers using the original service won't notice any difference, so they still get top-quality service.
- This method can be used in many different AI models and situations.
- It could also help companies track if their own employees are sharing things they shouldn’t.
In summary, this invisible marking system is like a shield for AI models in the cloud. It makes sure companies' hard work is safe, stops people from cheating, and helps the whole AI industry stay fair and trustworthy. While it's not perfect, it's a big step forward in keeping AI models secure.
Critically Analyzing the Priorities of Companies Like Microsoft
While the invisible marking system is an innovative way to safeguard AI models, there's a more fundamental issue many companies are overlooking: the ethical and legal implications of training these models on copyrighted data. Often, AI models like GPT-4 are trained on vast datasets that include copyrighted materials, like books, articles, or artwork. This training process might infringe on the rights of artists, authors, and other content creators, leading to significant legal and ethical quandaries.
These creators often don't consent to their work being used in such a manner, and it denies them the rightful recognition or compensation they deserve. It's imperative that companies prioritize the sourcing of their training data ethically, ensuring it respects copyrights and intellectual property rights.
Before adopting advanced protection measures for the models, the first step should be to ensure that these models aren't built upon the unrecognized or uncompensated work of others. The industry must acknowledge and address this foundational issue, ensuring AI advancements are both technologically and ethically sound.
Sources:
ACL 2023 — Area Chair Awards — NLP Applications: Are You Copying My Model? Protecting the Copyright of Large Language Models for EaaS via Backdoor Watermark

