
As AI technologies continue to advance at a rapid pace, business leaders must stay informed about the latest trends and developments to make strategic decisions about AI adoption and deployment. The 2024 AI Index Report from the Stanford Institute for Human-Centered Artificial Intelligence (HAI) offers valuable insights into the current state of AI benchmarks, which are standardized tests used to evaluate the performance of AI systems. In this article, we'll dive into the key findings of the report, focusing on benchmarks for truthfulness, reasoning, and agent-based systems, and explore their implications for businesses.
The Importance of Evolving Benchmarks
AI benchmarks play a crucial role in assessing the capabilities of AI systems and tracking progress over time. However, as AI models become more sophisticated, traditional benchmarks like ImageNet (for image recognition) and SQuAD (for question answering) are becoming less effective at differentiating state-of-the-art systems. This saturation has led researchers to develop more challenging benchmarks that better reflect real-world performance requirements. For business leaders, it's essential to understand that relying solely on outdated benchmarks may not provide an accurate picture of an AI solution's true capabilities.
Truthfulness Benchmarks: Ensuring Reliable AI-Generated Content
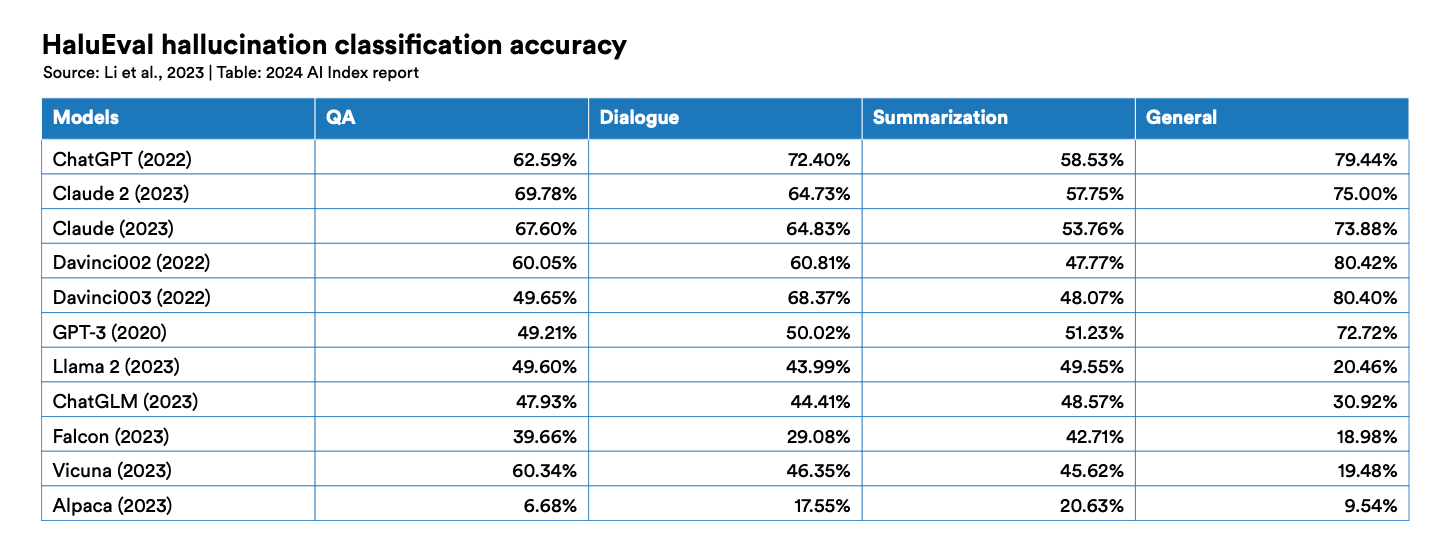
One of the key concerns for businesses looking to deploy AI solutions is the truthfulness and reliability of AI-generated content. With the rise of powerful language models like GPT-4, the risk of AI systems producing false or misleading information (known as "hallucinations") has become a significant challenge. Benchmarks like TruthfulQA and HaluEval have been developed to evaluate the factuality of language models and measure their propensity for hallucination.
TruthfulQA, for example, tests a model's ability to generate truthful answers to questions, while HaluEval assesses the frequency and severity of hallucinations across various tasks like question answering and text summarization. Business leaders should be aware of these benchmarks and consider them when evaluating AI solutions for content generation and decision support, particularly in industries where accuracy is critical, such as healthcare, finance, and legal services.
Reasoning Benchmarks: Assessing AI's Problem-Solving Capabilities
As businesses explore the potential of AI for complex problem-solving and decision-making, understanding the reasoning capabilities of AI systems is crucial. The 2024 AI Index Report highlights several new benchmarks designed to test AI's ability to reason across different domains, such as visual reasoning, moral reasoning, and social reasoning.
One notable example is the MMMU (Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI), which evaluates AI systems' ability to reason across various academic disciplines using multiple input modalities (e.g., text, images, and tables). Another benchmark, GPQA (Graduate-Level Google-Proof Q&A Benchmark), tests AI's capacity to answer complex, graduate-level questions that cannot be easily found through a Google search.
While state-of-the-art models like GPT-4 and Gemini Ultra have demonstrated impressive performance on these benchmarks, they still fall short of human-level reasoning in many areas. Business leaders should monitor progress on these benchmarks to better assess the readiness of AI solutions for their specific use cases and understand the limitations of current AI reasoning capabilities.
Agent-Based Systems: Evaluating Autonomous AI Performance
Autonomous AI agents, which can operate independently in specific environments to accomplish goals, have significant potential for businesses across various domains, from customer service to supply chain optimization. The 2024 AI Index Report introduces AgentBench, a new benchmark designed to evaluate the performance of AI agents in interactive settings like web browsing, online shopping, and digital card games.
AgentBench also compares the performance of agents based on different language models, such as GPT-4 and Claude 2. The report finds that GPT-4-based agents generally outperform their counterparts, but all agents struggle with long-term reasoning, decision-making, and instruction-following. For businesses considering deploying AI agents, these findings underscore the importance of thorough testing and the need for human oversight and intervention.
Alignment Techniques: RLHF vs. RLAIF
As businesses deploy AI systems, ensuring that they behave in accordance with human preferences and values is a key concern. Reinforcement Learning from Human Feedback (RLHF) has emerged as a popular technique for aligning AI models with human preferences. RLHF involves training AI systems using human feedback to reward desired behaviors and punish undesired ones.
However, the 2024 AI Index Report also highlights a new alignment technique called Reinforcement Learning from AI Feedback (RLAIF), which uses feedback from AI models themselves to align other AI systems. Research suggests that RLAIF can be as effective as RLHF while being more resource-efficient, particularly for tasks like generating safe and harmless dialogue. For businesses, the development of more efficient alignment techniques like RLAIF could make it easier and less costly to deploy AI systems that behave in accordance with company values and objectives.
Emergent Behavior and Self-Correction: Challenging Common Assumptions
The 2024 AI Index Report also features research that challenges two common assumptions about AI systems: the notion of emergent behavior and the ability of language models to self-correct.
Emergent behavior refers to the idea that AI systems can suddenly develop new capabilities when scaled up to larger sizes. However, a study from Stanford suggests that the perceived emergence of new abilities may be more a reflection of the benchmarks used for evaluation rather than an inherent property of the models themselves. This finding emphasizes the importance of thoroughly testing and validating AI systems before deployment, rather than relying on assumptions about their potential for unexpected improvements.
Another study highlighted in the report investigates the ability of language models to self-correct their reasoning. While self-correction has been proposed as a solution to the limitations and hallucinations of language models, the research finds that models like GPT-4 struggle to autonomously correct their reasoning without external guidance. This underscores the ongoing need for human oversight and the development of external correction mechanisms.
Techniques for Improving Language Models
As businesses deploy language models for various applications, from customer service to content creation, the efficiency and performance of these models become critical considerations. The 2024 AI Index Report showcases several promising techniques for enhancing the performance of language models:
- Graph of Thoughts (GoT) Prompting: A prompting method that enables language models to reason more flexibly by modeling their thoughts in a graph-like structure, leading to improved output quality and reduced computational costs.
- Optimization by PROmpting (OPRO): A technique that uses language models to iteratively generate prompts that improve algorithmic performance on specific tasks.
- QLoRA Fine-Tuning: A fine-tuning method that significantly reduces the memory requirements for adapting large language models to specific tasks, making the process more efficient and accessible.
- Flash-Decoding Optimization: An optimization technique that speeds up the inference process for language models, particularly in tasks requiring long sequences, by parallelizing the loading of keys and values.
By staying informed about these developments, business leaders can make more strategic decisions about their AI investments and implementations, prioritizing techniques that enhance performance, reduce costs, and align with their specific use cases.
Conclusion
The 2024 AI Index Report offers valuable insights into the evolving landscape of AI benchmarks and their implications for businesses. As AI systems become more powerful and ubiquitous, it is crucial for business leaders to understand the latest trends in benchmarking, alignment techniques, and performance optimization.
By monitoring progress on benchmarks for truthfulness, reasoning, and agent-based systems, businesses can better assess the capabilities and limitations of AI solutions and make informed decisions about their adoption and deployment. Additionally, staying attuned to developments in alignment techniques like RLAIF and performance optimization methods like GoT prompting and Flash-Decoding can help businesses navigate the complex landscape of AI and harness its potential for growth and innovation.
Ultimately, the key takeaway for business leaders is the importance of thorough testing, validation, and ongoing monitoring of AI systems. By relying on the latest benchmarks, challenging assumptions about emergent behavior and self-correction, and prioritizing human oversight and external correction mechanisms, businesses can responsibly and effectively leverage AI technologies to drive their success in an increasingly competitive landscape.


