
Artificial intelligence has become very capable at summarizing text. But current models are still trained indirectly - to mimic human reference summaries, not to directly satisfy users.
Researchers at OpenAI investigated whether getting regular people to compare AI-generated summaries can produce higher quality models.
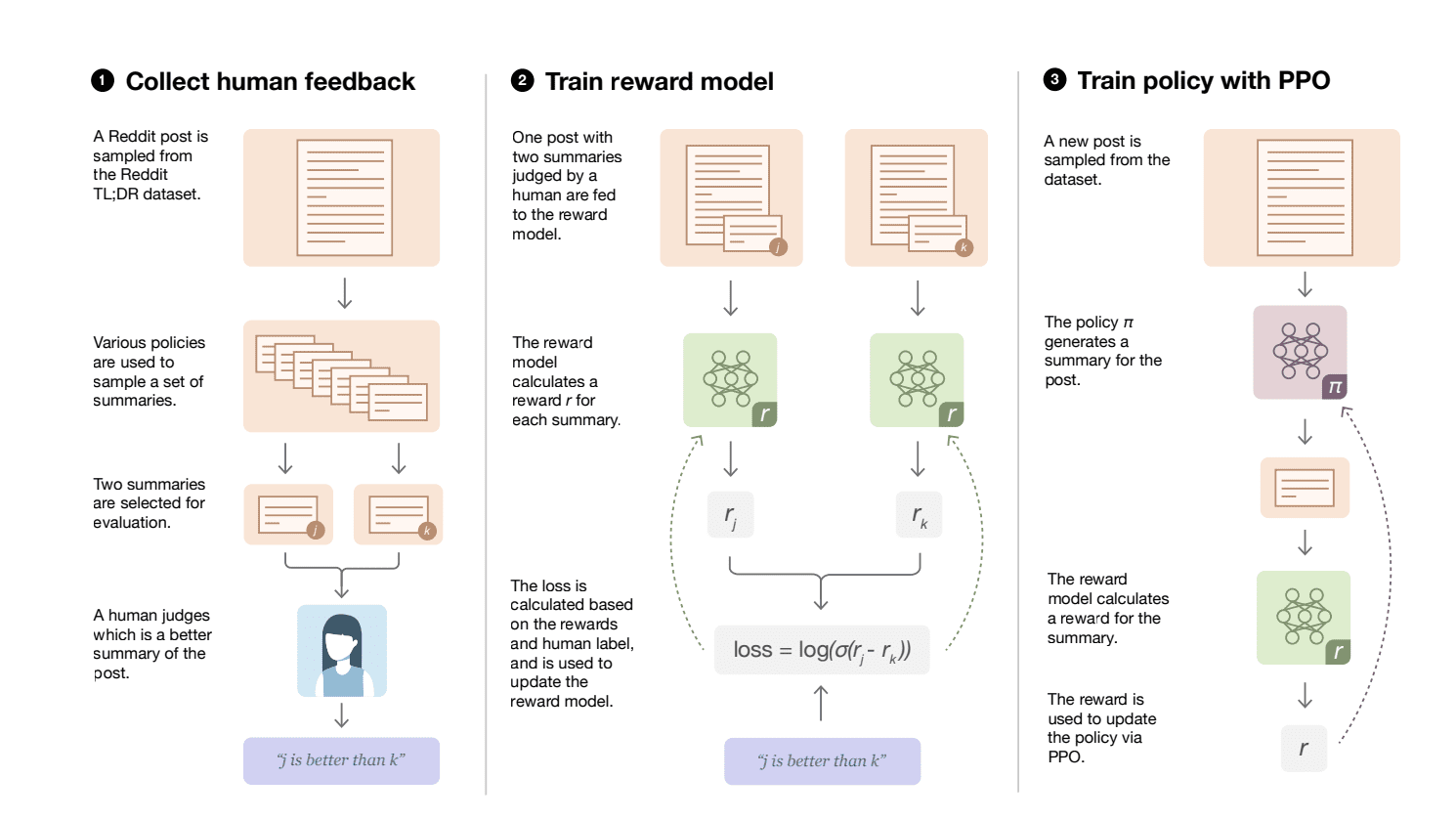
Their technique worked as follows:
- They built a text summarization system based on a neural network language model.
- For each piece of text, the system generated multiple summary options.
- They showed human evaluators pairs of summaries for the same text and had them pick the better one.
- They used these comparisons to train a separate "reward model" to predict which summary humans would prefer.
- They then used this reward model to fine-tune the main summarization system, via a reinforcement learning algorithm. The system learns to generate summaries that score highly on the reward model.
- By repeating this loop of gathering feedback, training the reward model, and tuning the summarizer, the system improves over time.
The researchers found that optimizing the AI for direct human preferences significantly boosted performance compared to just training it to mimic reference summaries.
With enough feedback data, the AI's summaries surpassed the quality of the original human-written summaries used for training.
The key is the tight feedback loop between users and the system - the AI learns dynamically what people see as a high quality summary.
This technique provides a template for any application where humans can evaluate outputs, like speech or translation. The AI learns to satisfy users, not just match a benchmark.
For business leaders, it shows the value of measuring how well AI fulfills human needs, beyond just technical metrics. As AI advances, aligning it with people may require creative feedback techniques like this.
Source:


