A new study has shown that transformers can be expressed in a simple logic formalism. This finding challenges the perception that transformers are inscrutable black boxes and suggests avenues for interpreting how they work.
A new study has shown that transformers can be expressed in a simple logic formalism. This finding challenges the perception that transformers are inscrutable black boxes and suggests avenues for interpreting how they work.
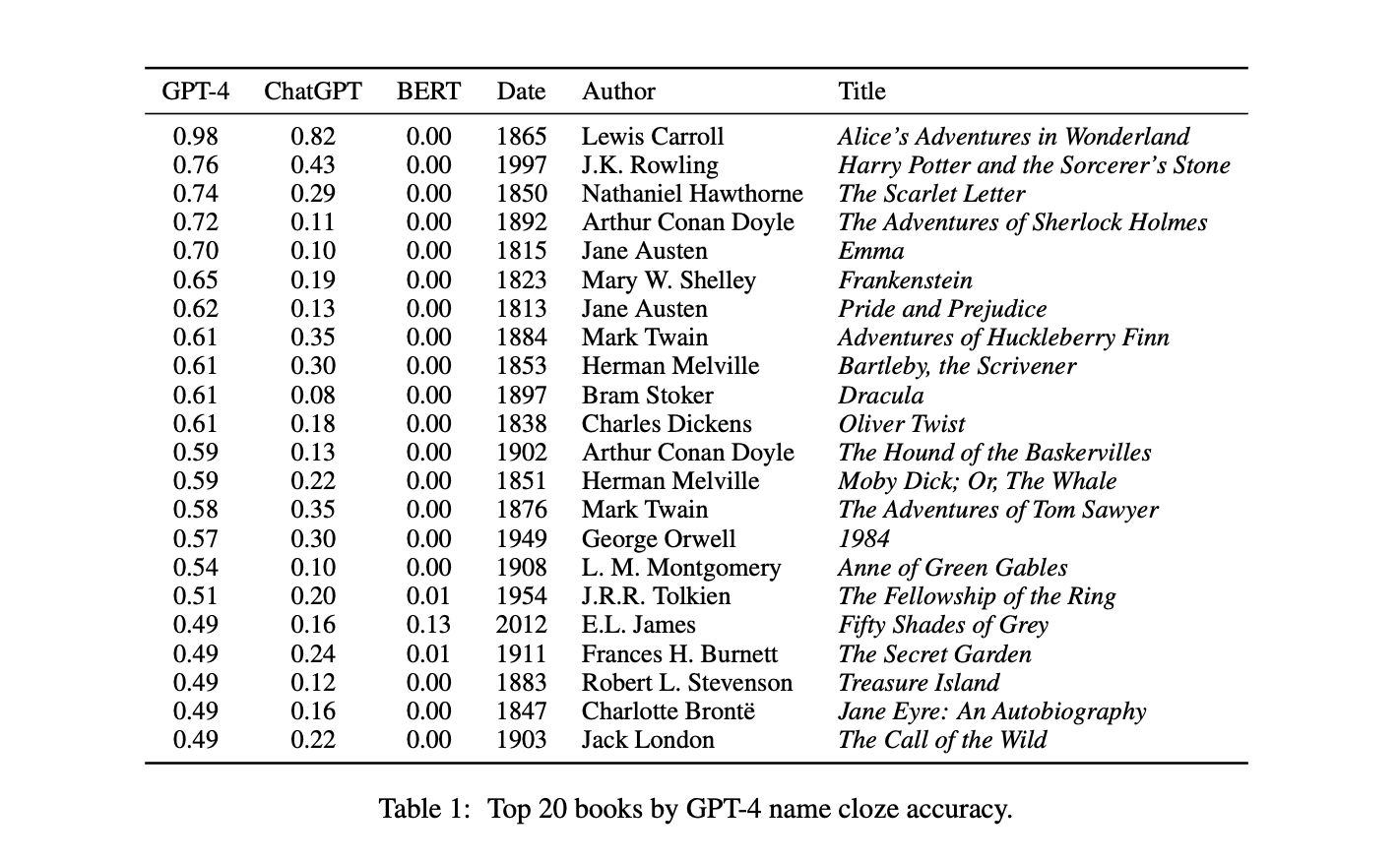
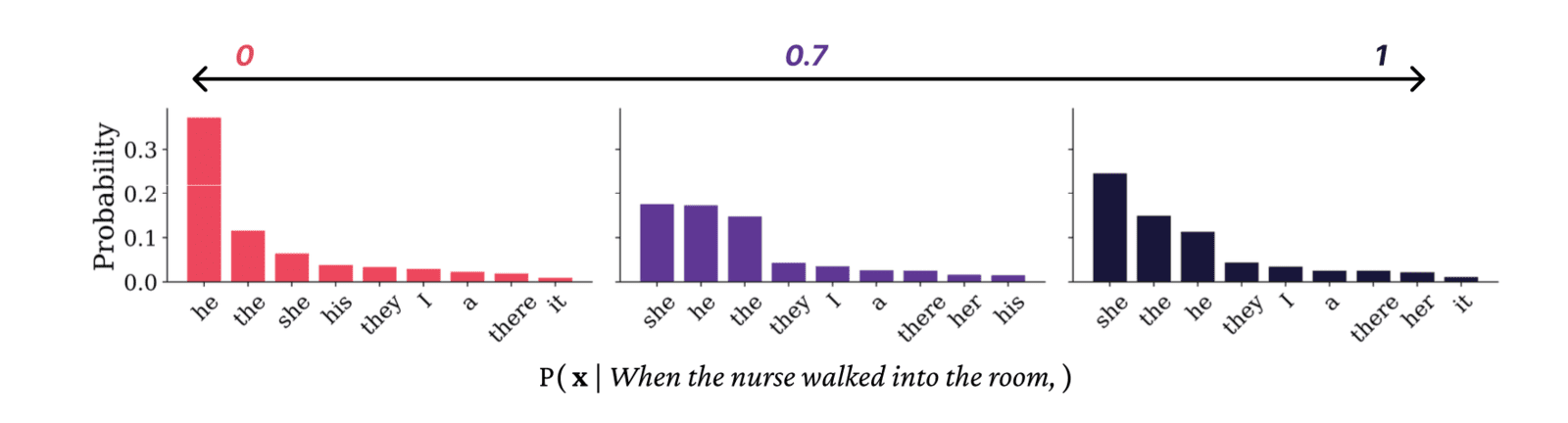
New research from the University of California, Berkeley sheds light on one slice of these models' knowledge: which books they have "read" and memorized. The study uncovers systematic biases in what texts AI systems know most about.