
Blog tagged as #AIStoryBrain

Ines Almeida
11.08.23 10:04 AM - Comment(s)
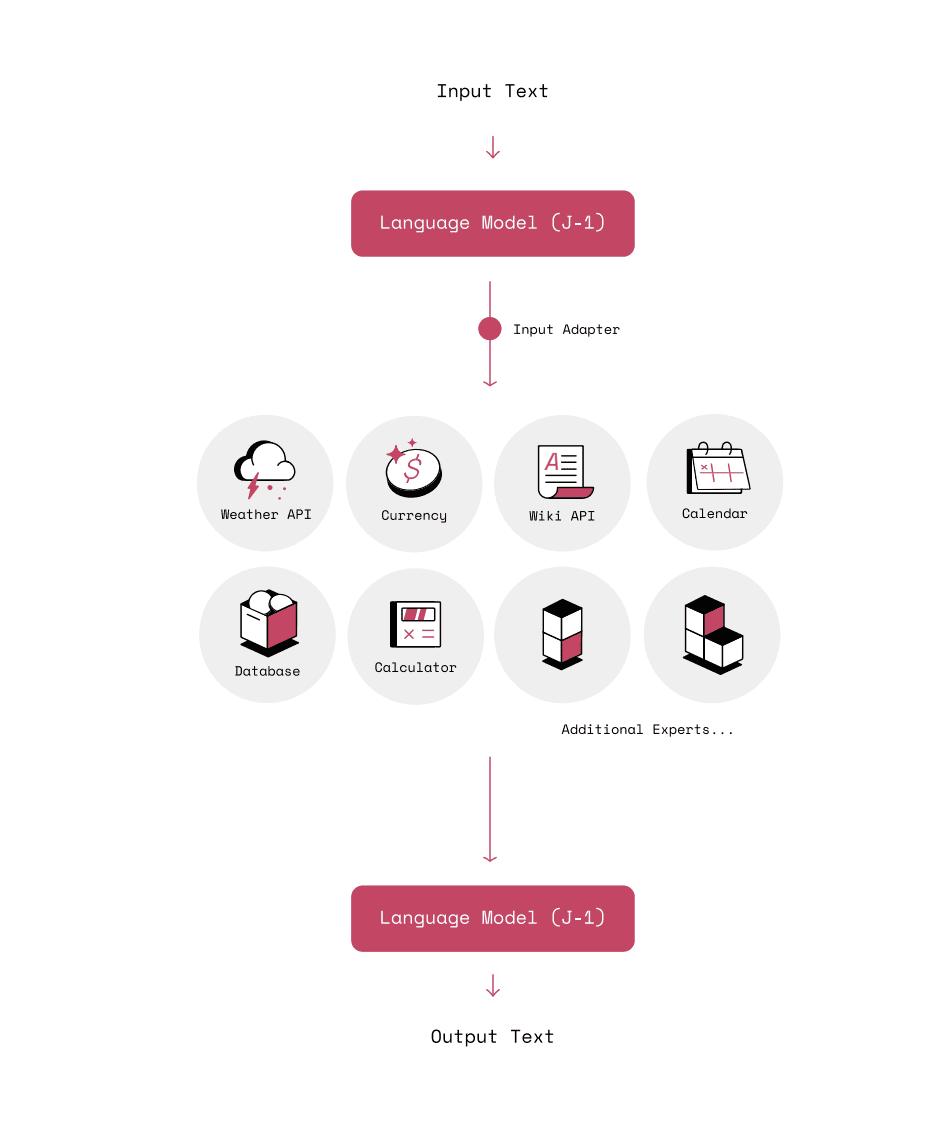
Ines Almeida
10.08.23 09:21 PM - Comment(s)
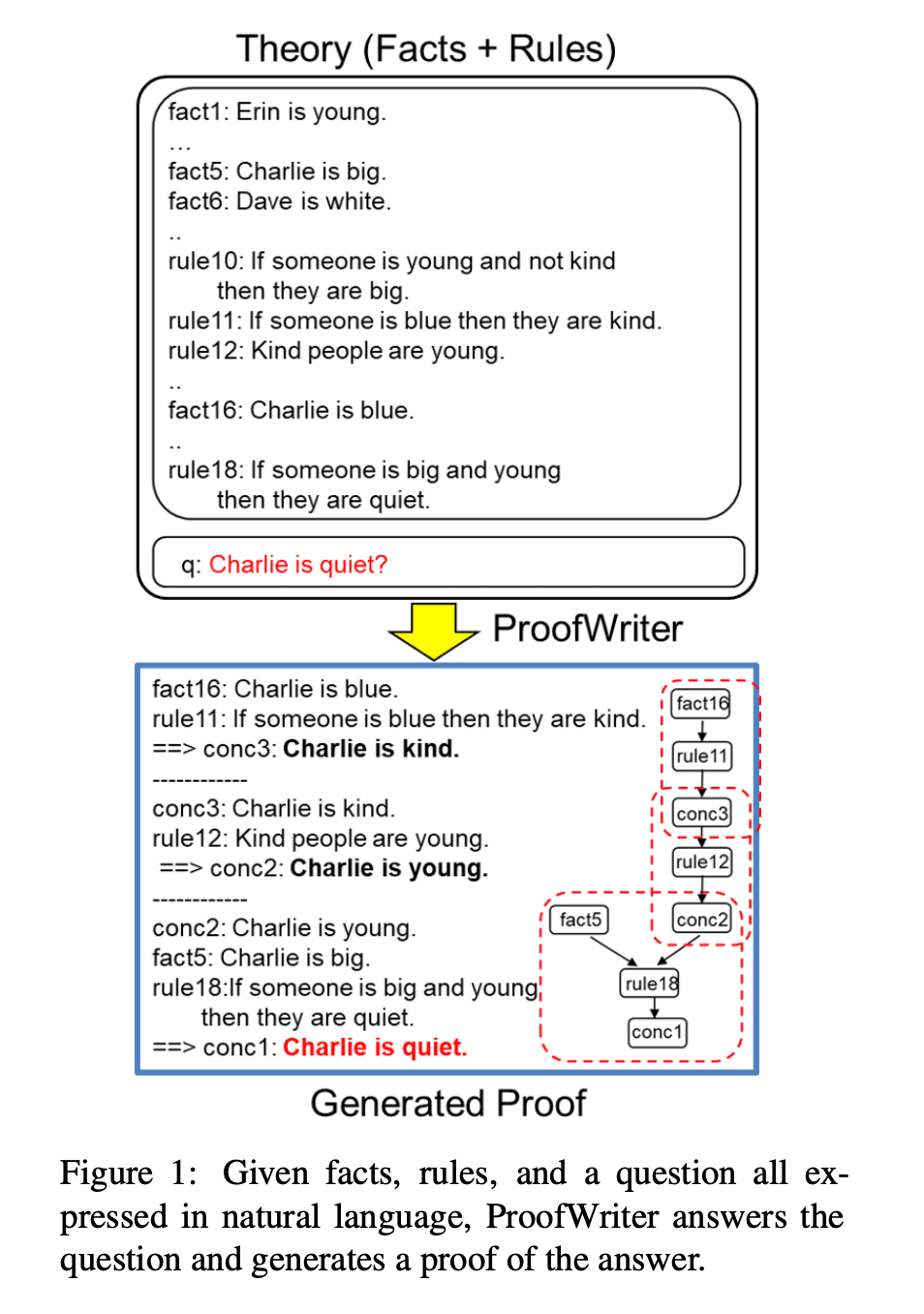
Ines Almeida
10.08.23 06:34 PM - Comment(s)
Researchers have developed a benchmark called the LAMBADA dataset to rigorously test how well AI models can leverage broader discourse context when predicting an upcoming word.
Ines Almeida
10.08.23 08:08 AM - Comment(s)
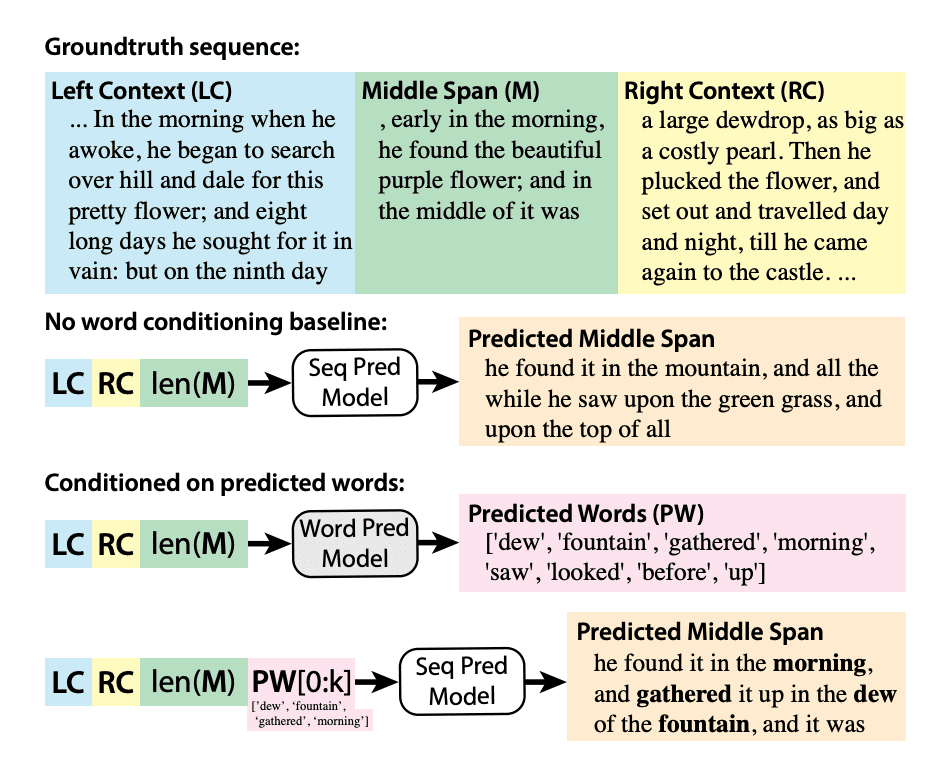
Ines Almeida
10.08.23 08:07 AM - Comment(s)

Ines Almeida
10.08.23 08:07 AM - Comment(s)
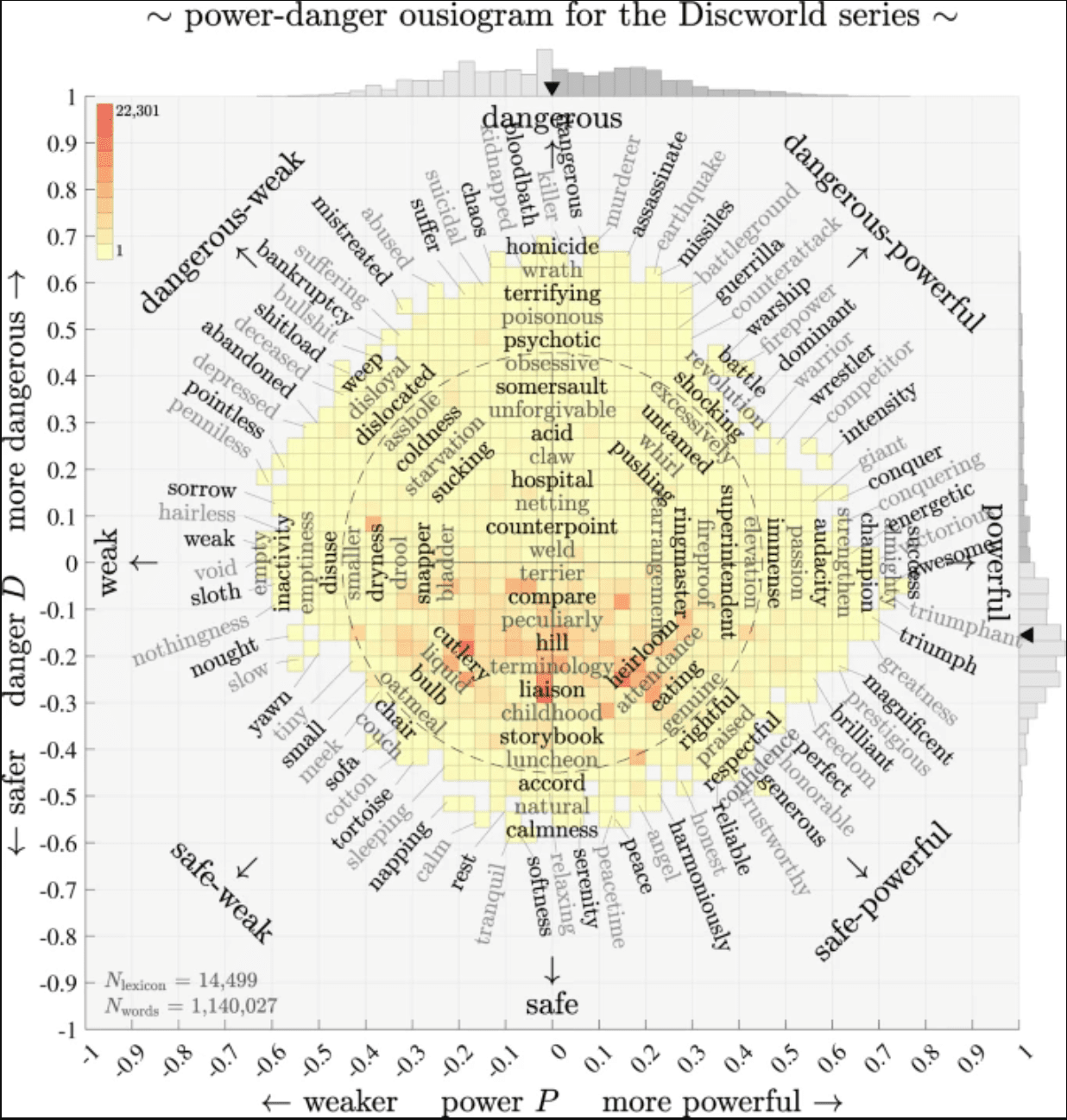
Ines Almeida
10.08.23 08:06 AM - Comment(s)
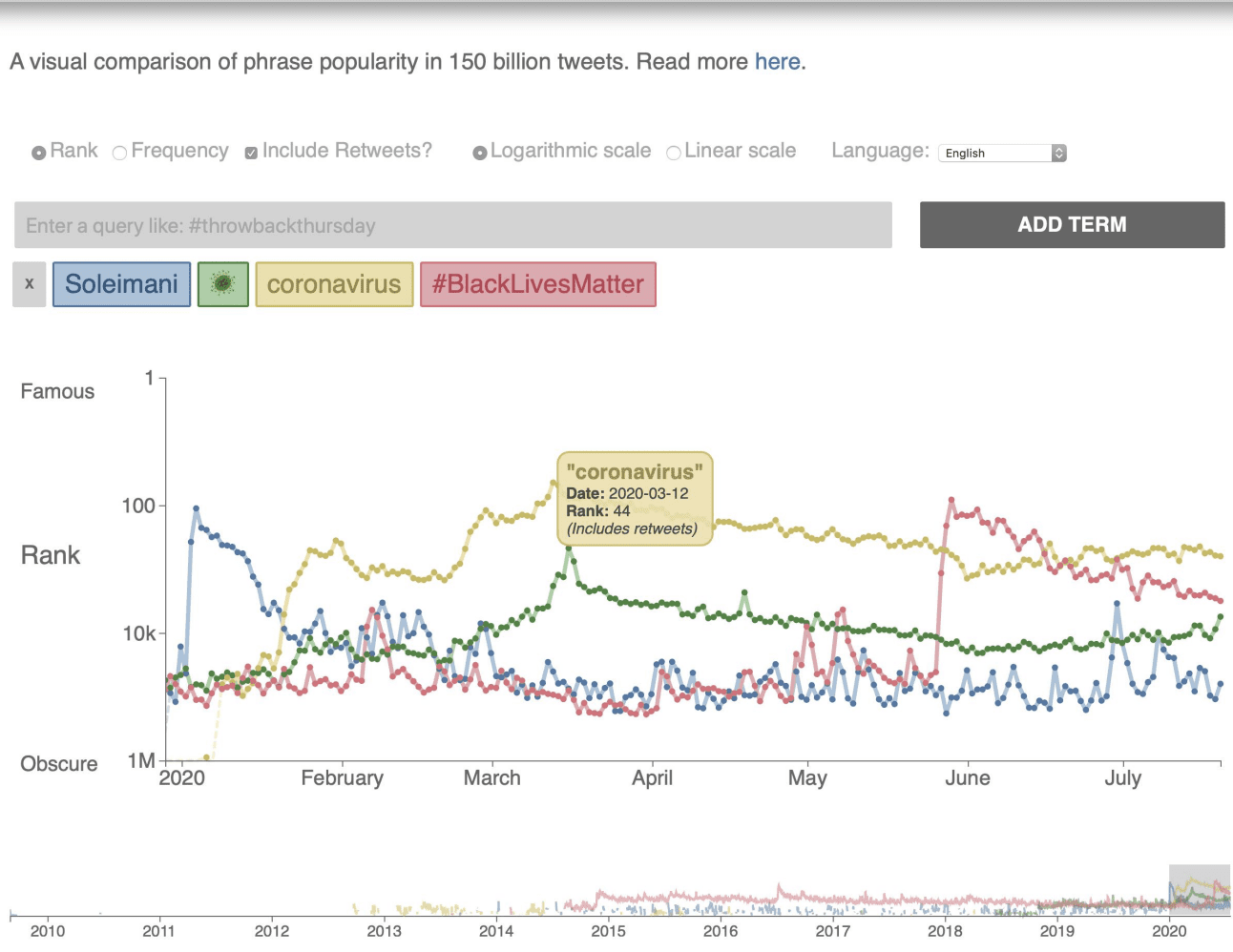
Ines Almeida
10.08.23 08:05 AM - Comment(s)
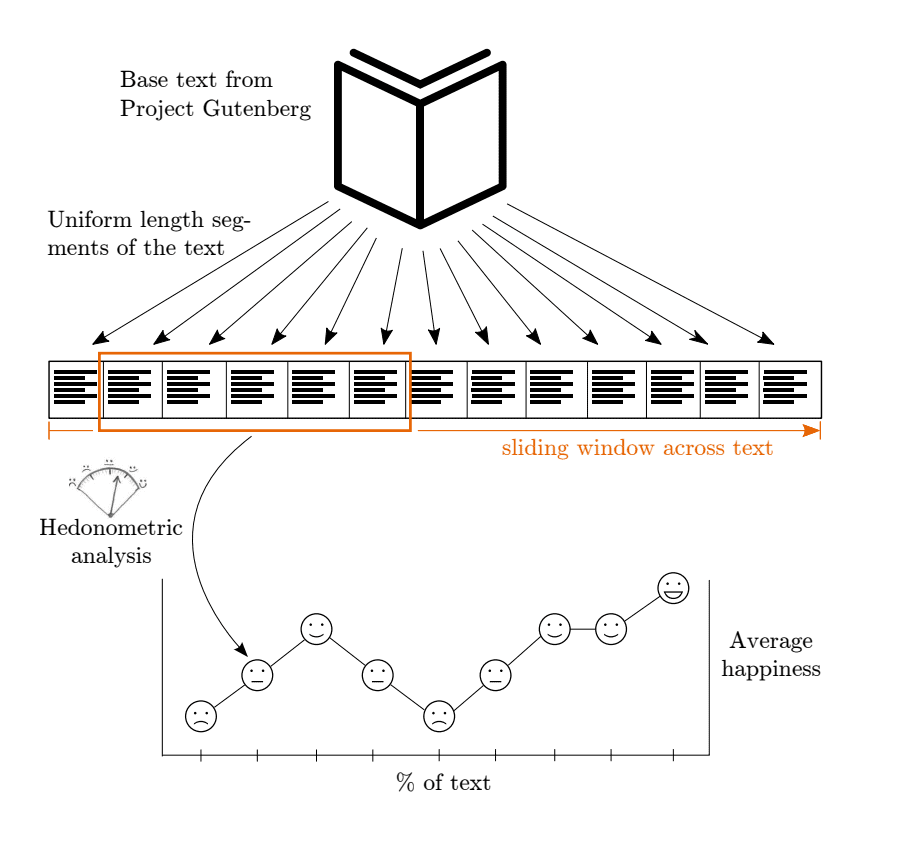
Ines Almeida
10.08.23 08:05 AM - Comment(s)
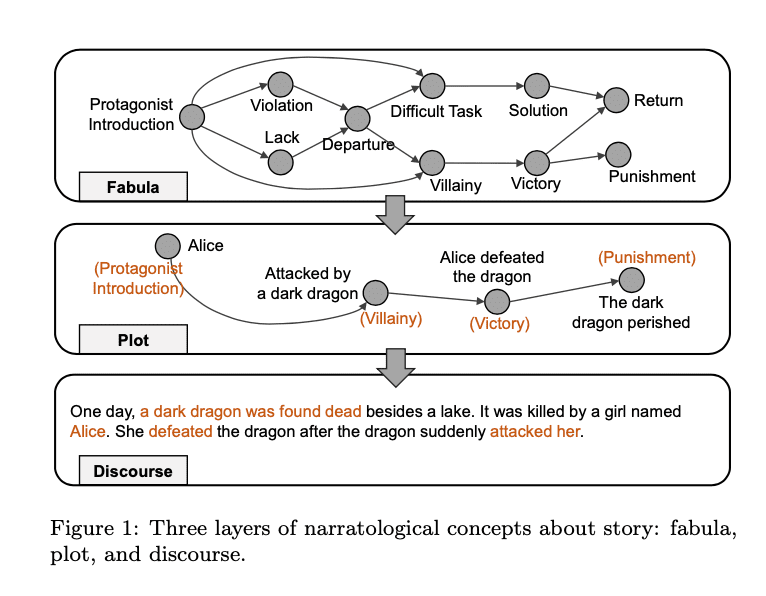
Ines Almeida
10.08.23 08:05 AM - Comment(s)
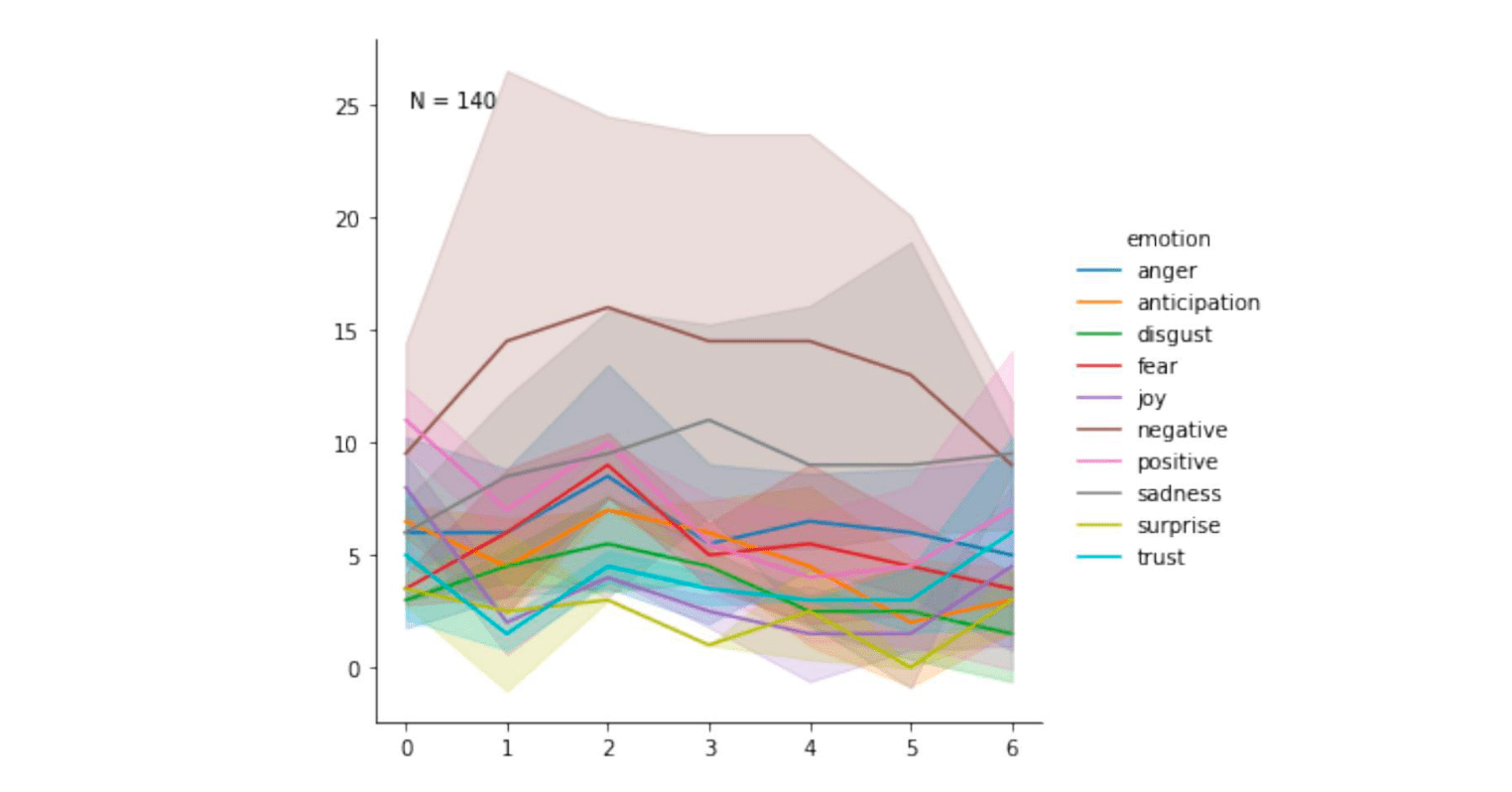
Ines Almeida
10.08.23 08:04 AM - Comment(s)
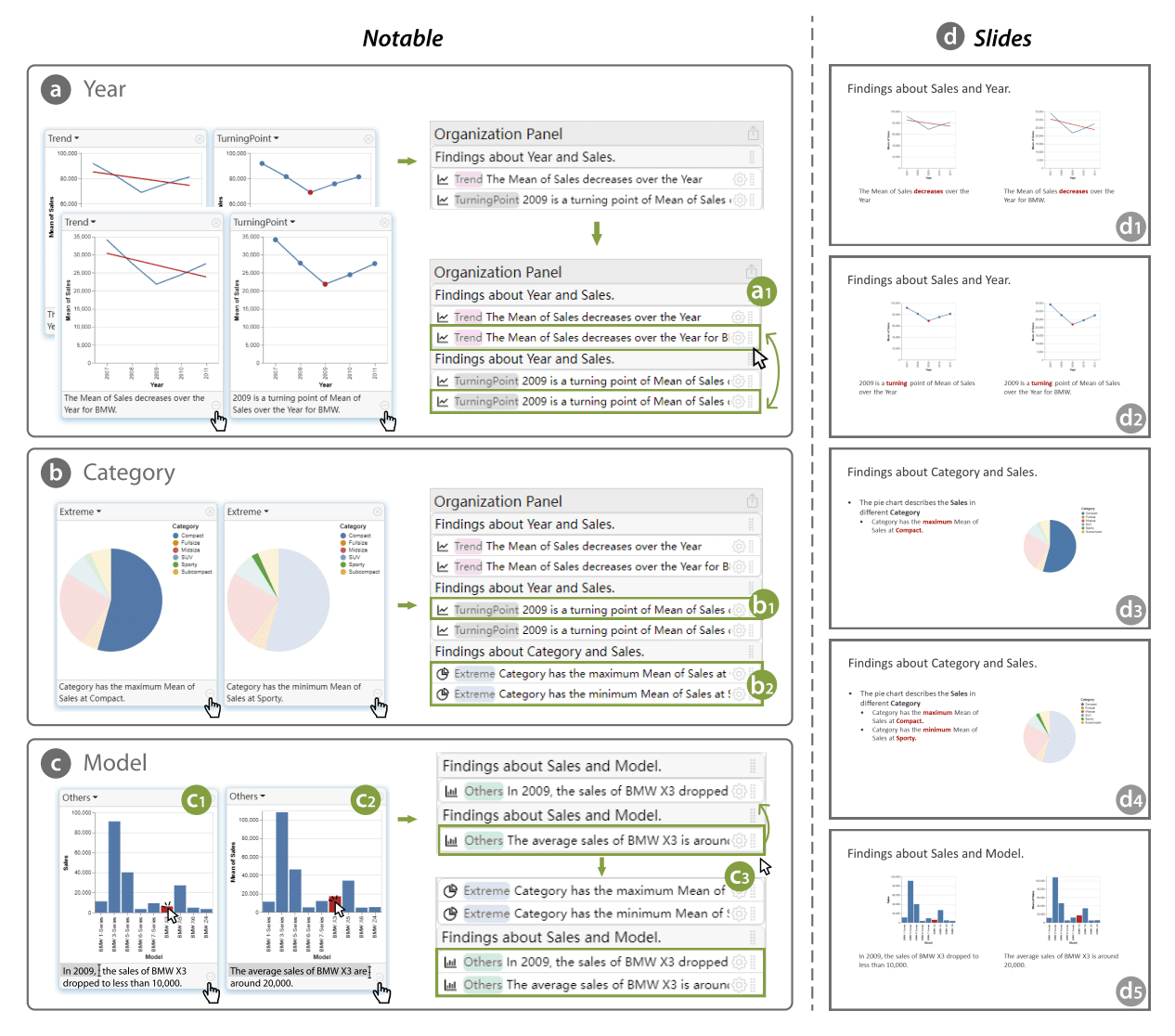
Ines Almeida
10.08.23 08:04 AM - Comment(s)
Back in 2018, researchers from Facebook AI developed a new method to improve story generation through hierarchical modeling. Their approach mimics how people plan out narratives.
Ines Almeida
10.08.23 08:03 AM - Comment(s)
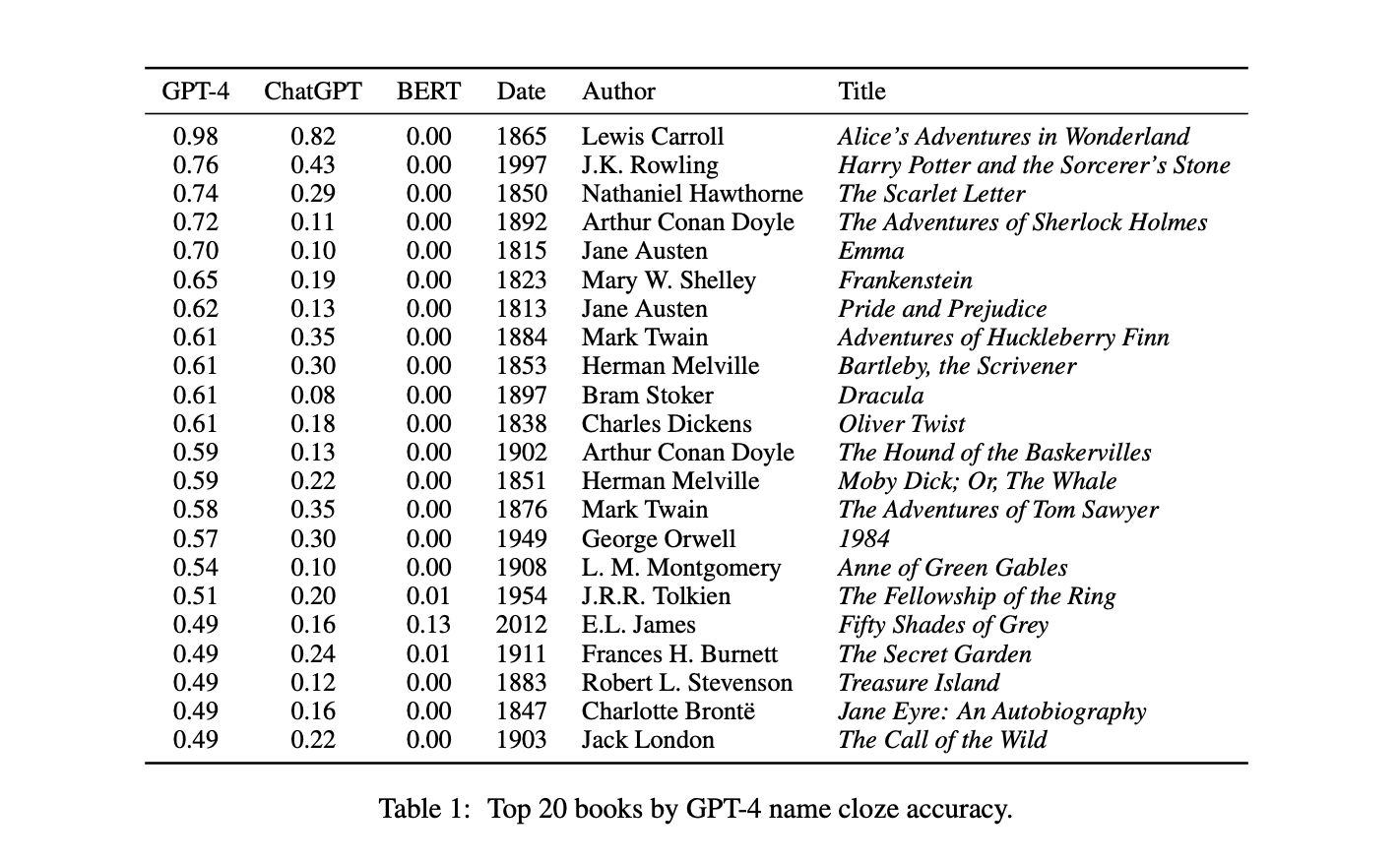
Ines Almeida
10.08.23 08:03 AM - Comment(s)
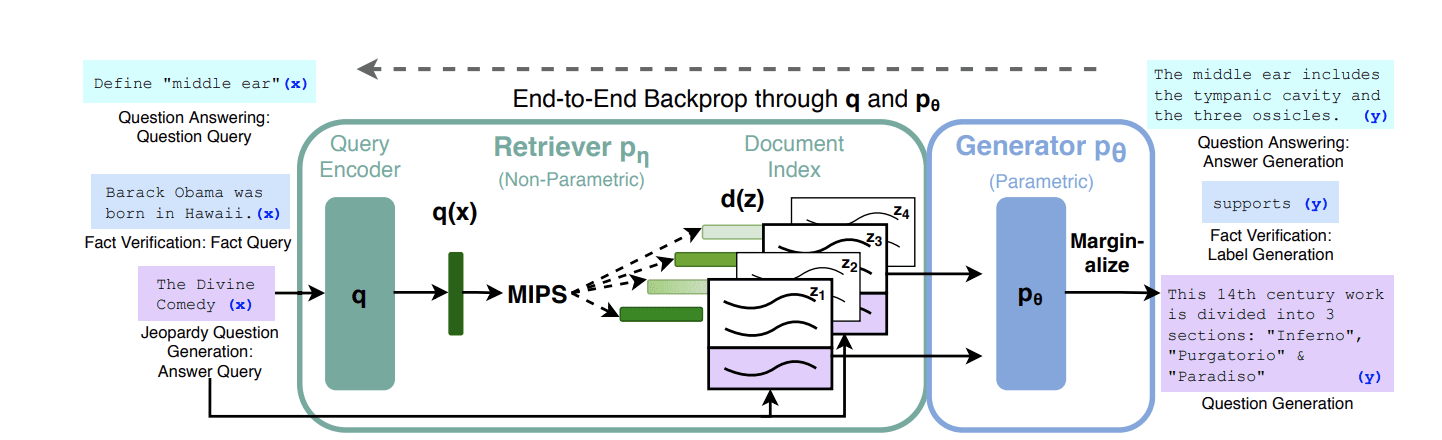
Ines Almeida
10.08.23 08:03 AM - Comment(s)

Ines Almeida
09.08.23 10:57 PM - Comment(s)
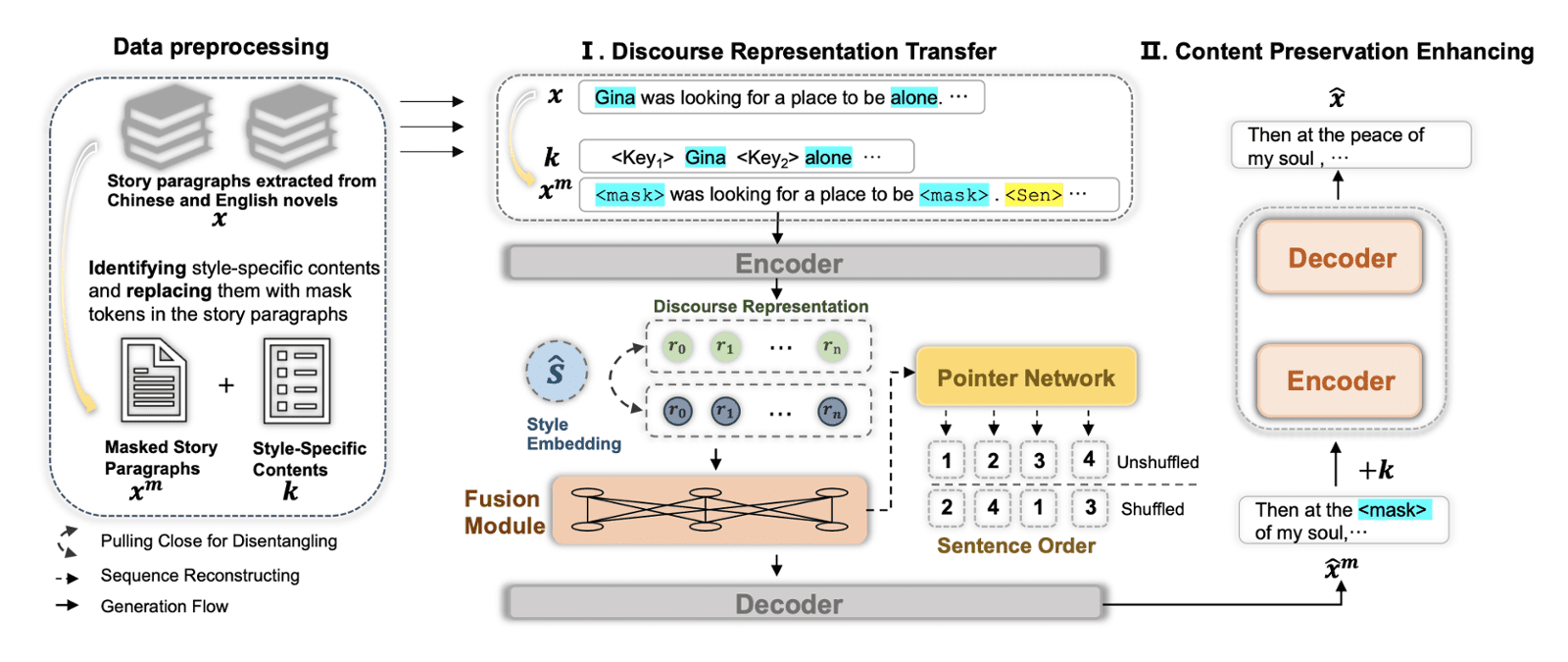
Ines Almeida
08.08.23 10:40 PM - Comment(s)

