
Blog tagged as Responsible AI

LLMs currently face significant challenges when it comes to truthfulness. Understanding these limitations is essential for any business considering leveraging LLMs.
Ines Almeida
29.04.24 01:00 PM - Comment(s)

We explore the current state of responsible AI, examining the lack of standardized evaluations for LLMs, the discovery of complex vulnerabilities in these models, the growing concern among businesses about AI risks, and the challenges posed by LLMs outputting copyrighted material.
Ines Almeida
29.04.24 11:19 AM - Comment(s)

A new study from Harvard University reveals how LLMs can be manipulated to boost a product's visibility and ranking in recommendations.
Ines Almeida
15.04.24 02:00 PM - Comment(s)
InterpretML is a valuable tool for unlocking the power of interpretable AI in traditional machine learning models. While it may have limitations when it comes to directly interpreting LLMs, the principles of interpretability and transparency remain crucial in the age of generative AI.
Ines Almeida
04.04.24 12:45 PM - Comment(s)

It is crucial for business leaders to understand the limitations and potential pitfalls of current approaches to measuring AI capabilities.
Ines Almeida
03.04.24 10:42 AM - Comment(s)
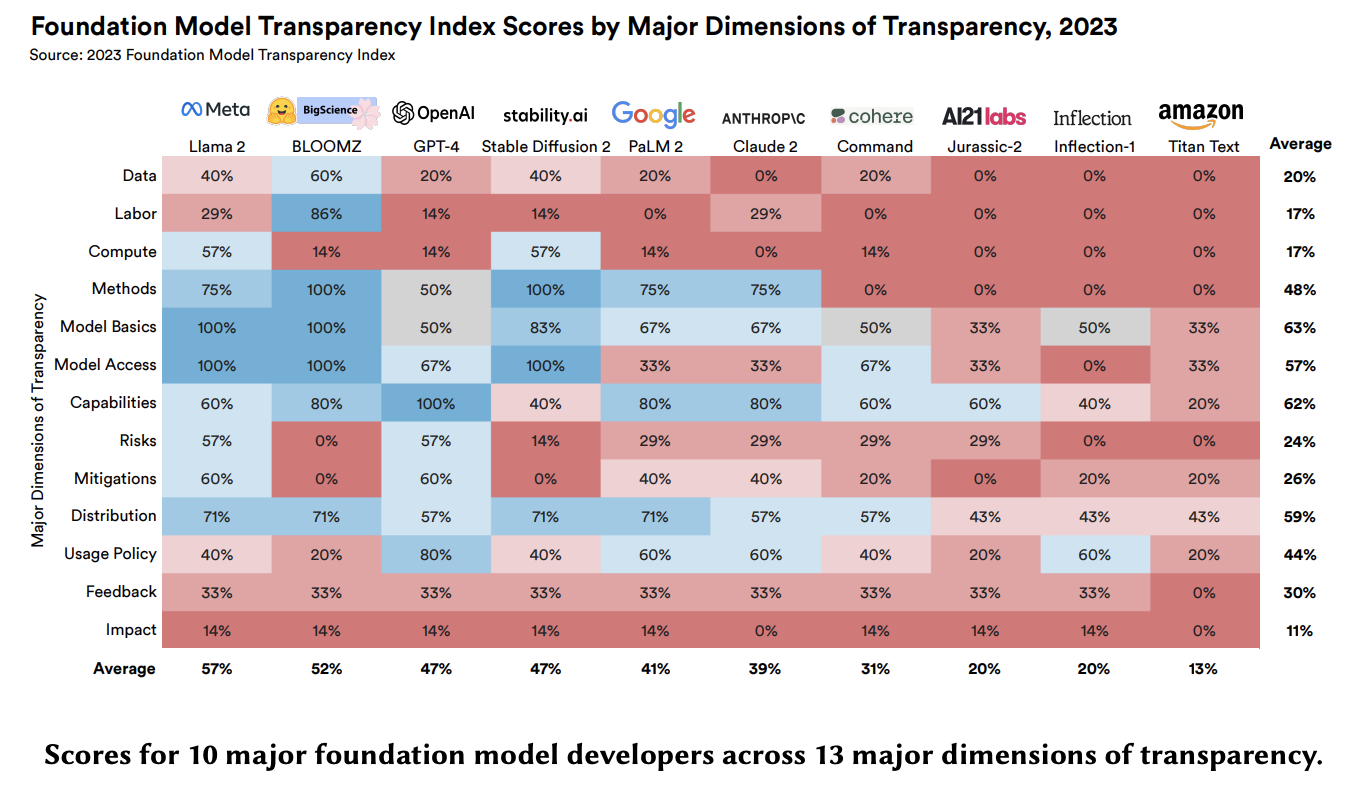
A recent critique calls into question a prominent AI transparency benchmark, illustrating the challenges in evaluating something as complex as transparency.
Ines Almeida
01.11.23 12:07 PM - Comment(s)
A recent critique calls into question a prominent AI transparency benchmark, illustrating the challenges in evaluating something as complex as transparency.
Ines Almeida
01.11.23 12:07 PM - Comment(s)

Ines Almeida
16.08.23 09:04 AM - Comment(s)
Ines Almeida
13.08.23 10:39 PM - Comment(s)
A thought-provoking paper from computer scientists raises important concerns about the AI community's pursuit of ever-larger language models.
Ines Almeida
13.08.23 09:46 PM - Comment(s)
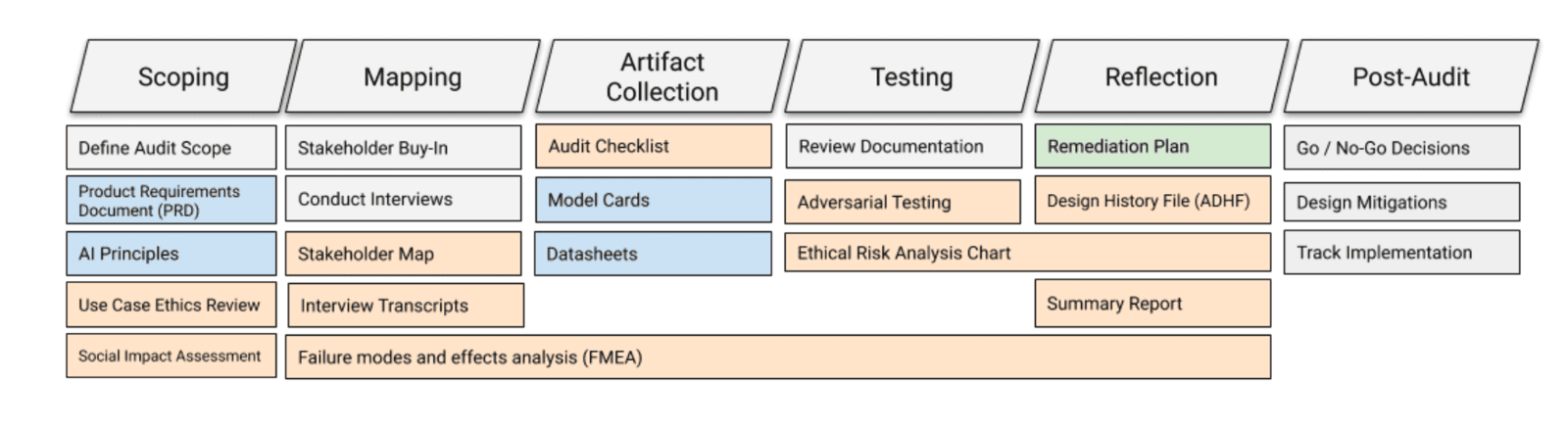
Ines Almeida
13.08.23 08:31 PM - Comment(s)
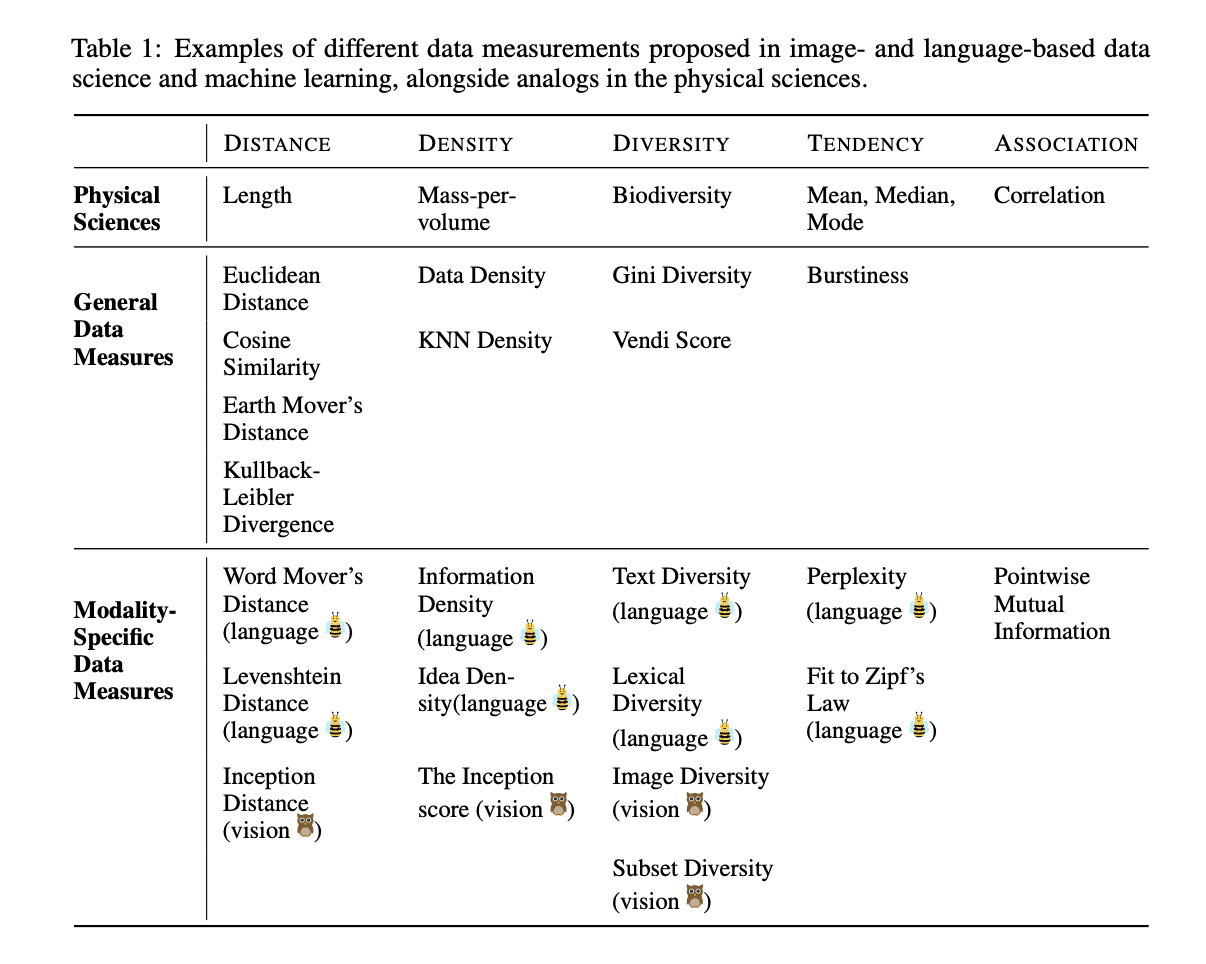
Ines Almeida
13.08.23 08:14 PM - Comment(s)
A study from AI researchers at OpenAI demonstrates how large language models like chatbots can be adapted to reflect specific societal values through a simple "fine-tuning" process.
Ines Almeida
13.08.23 08:03 PM - Comment(s)
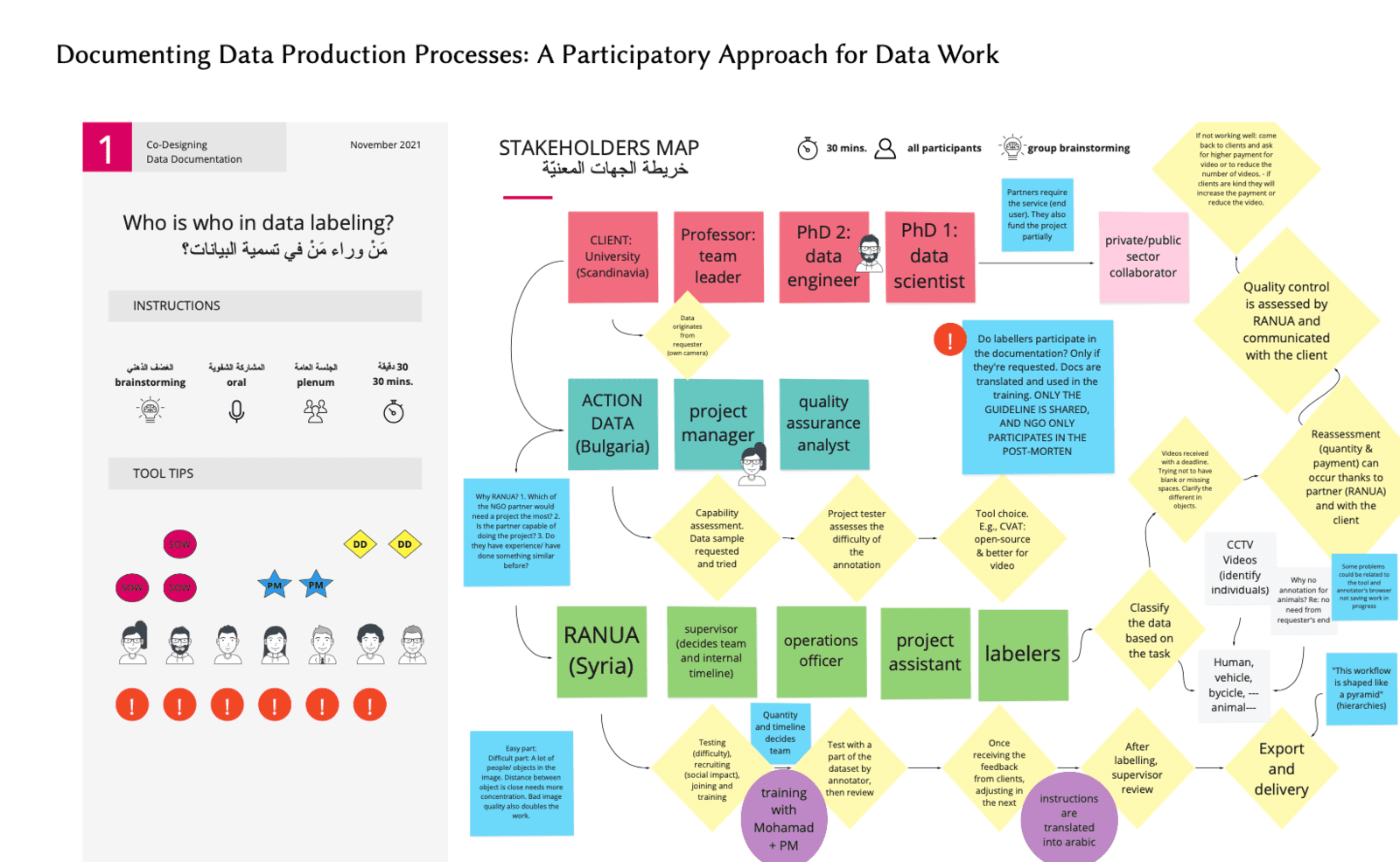
Ines Almeida
13.08.23 12:31 PM - Comment(s)
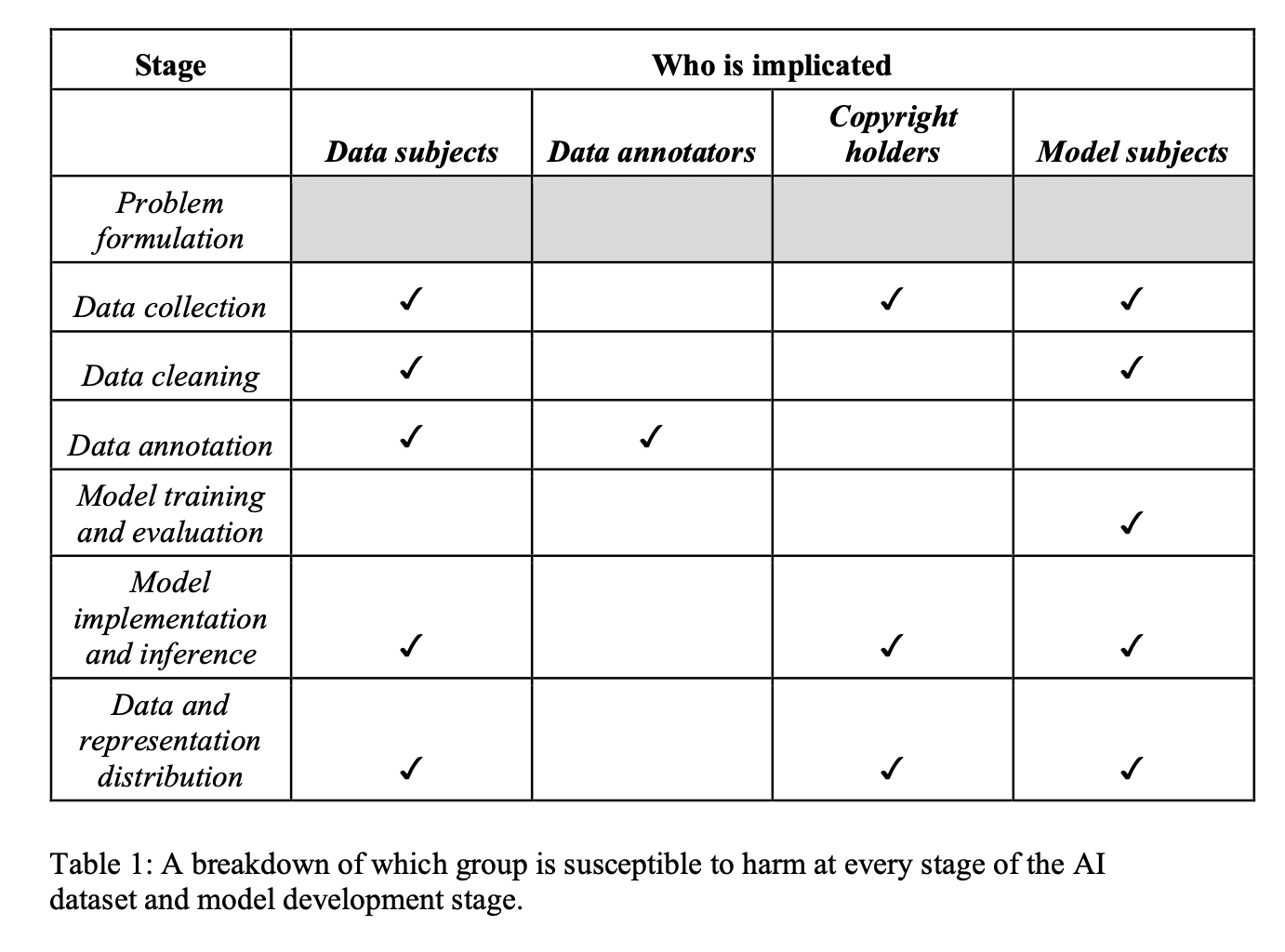
Ines Almeida
13.08.23 11:51 AM - Comment(s)
Machine learning models rely heavily on their training datasets, inheriting inherent biases and limitations. This research proposes "datasheets for datasets" increasing transparency and mitigating risks.
Ines Almeida
13.08.23 11:21 AM - Comment(s)

Ines Almeida
13.08.23 05:47 AM - Comment(s)

Ines Almeida
12.08.23 09:22 AM - Comment(s)
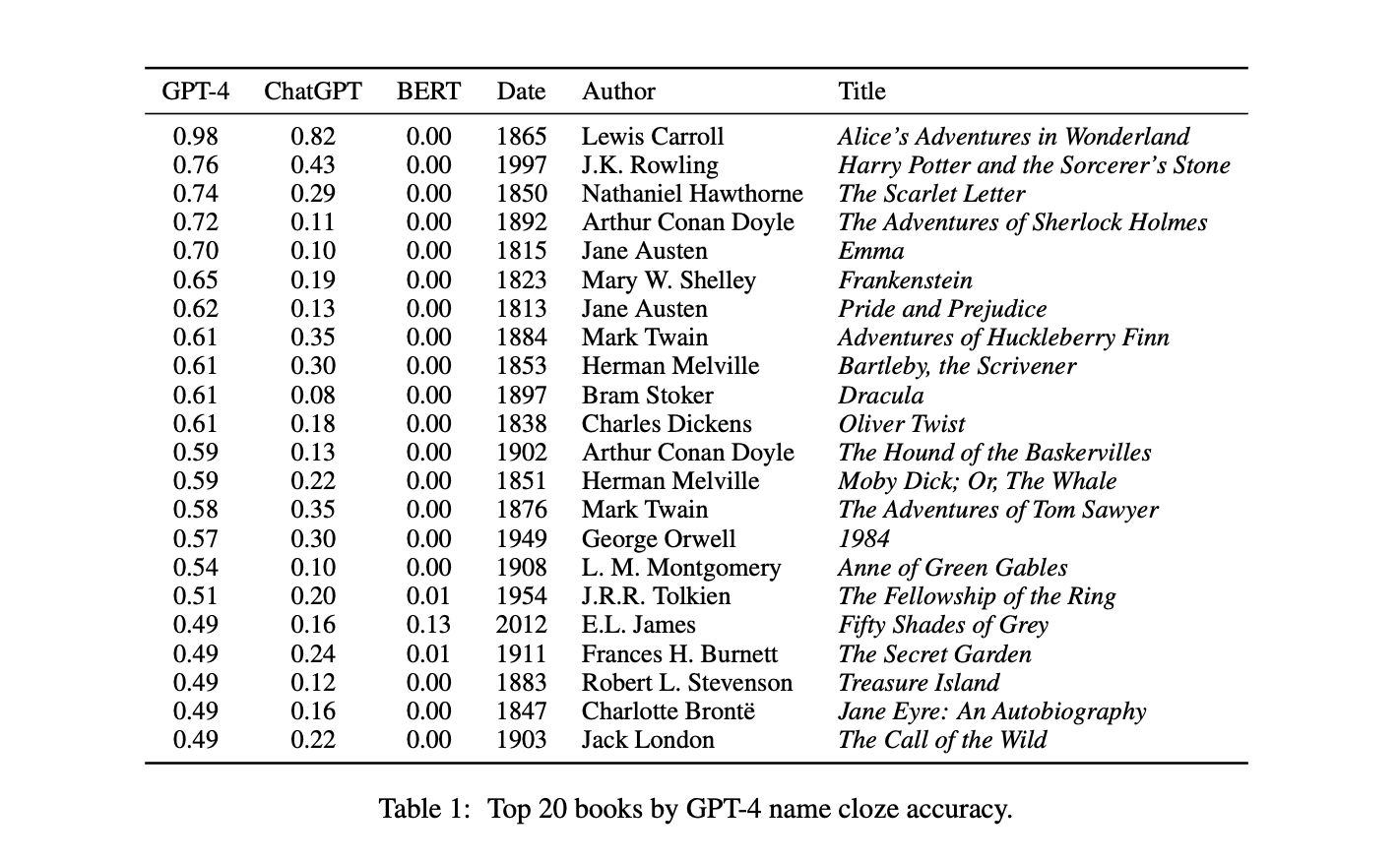
Ines Almeida
10.08.23 08:03 AM - Comment(s)
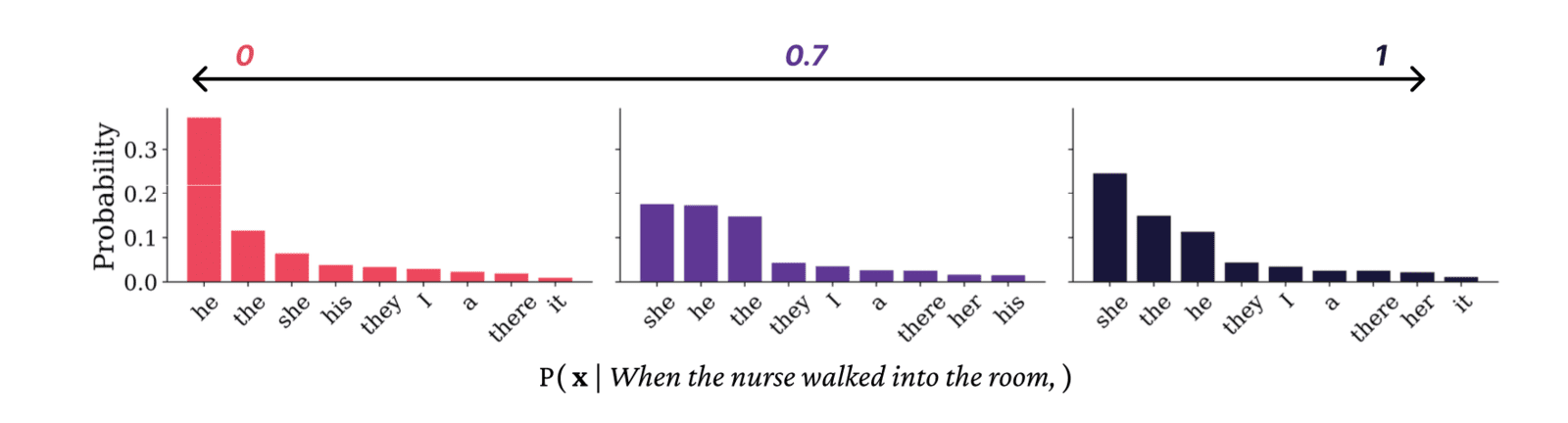
Ines Almeida
10.08.23 07:59 AM - Comment(s)

